Magento 2 - Elastic Search Concepts for a Magento Developer
Related Articles
- How to Enable 'eq' Filter GraphQL Search for an Custom Attribute of Type Text in Magento 2
- Magento 2 - Useful Elasticsearch Commands
- Magento 2 - How data is fetched from Elasticserach
- How Product Data is Pushed to Elasticsearch from Magento
- Elastic Search for Magento Developer
Elastic Search is a powerful search and analytics engine. It is known for its distributed nature, speed, and scalability. This document covers the important concepts of elastic search that would require for a magento developer
The Elasticsearch Instance
Once Elasticsearch is installed and running you have the instance of the Elasticsearch also known as node.
Elasticsearch Instance == Node
A node contains unique ID and Name and belongs to a single cluster. When you start elasticsearch instance (node) a cluster is automatically created. A cluster can have 1 to n nodes. Nodes can be distributed in several machines but still they can be part of single cluster.
Document
Elasticsearch stores data as JSON documents. Each document correlates a set of keys (names of fields or properties) with their corresponding values (strings, numbers, Booleans, dates, arrays of values, geolocations, or other types of data). Every document contains a unique ID
Indices
Document that shares similarities are grouped in to indices. Multiple Index can be stored in a node. Index is just a virtual thing that knows where the data is stored, Data is actually stored in the shard.
- MySQL => Databases => Tables => Columns/Rows
- Elasticsearch => Indices => Types => Documents with Properties
Shard
Shard is where data is stored, this is where you run your search query. When you create an index, a shard is created by default. No of documents that a shard can store depends on the size of the document and the instance size. Shards are horizontally scalable. A Single index can be stored across multiple nodes.
The total no of index you have in the node, the total no of shards will be created. This no can be changed based on the index.number_of_shards configuration.
Sharding
The practice of creating an index with multiple shards is called sharding. Its explained in the below image. Here we have elasticsearch with three instance and contains two indexes. These indexes are shared in all three instances. Each index contains 2 shards.
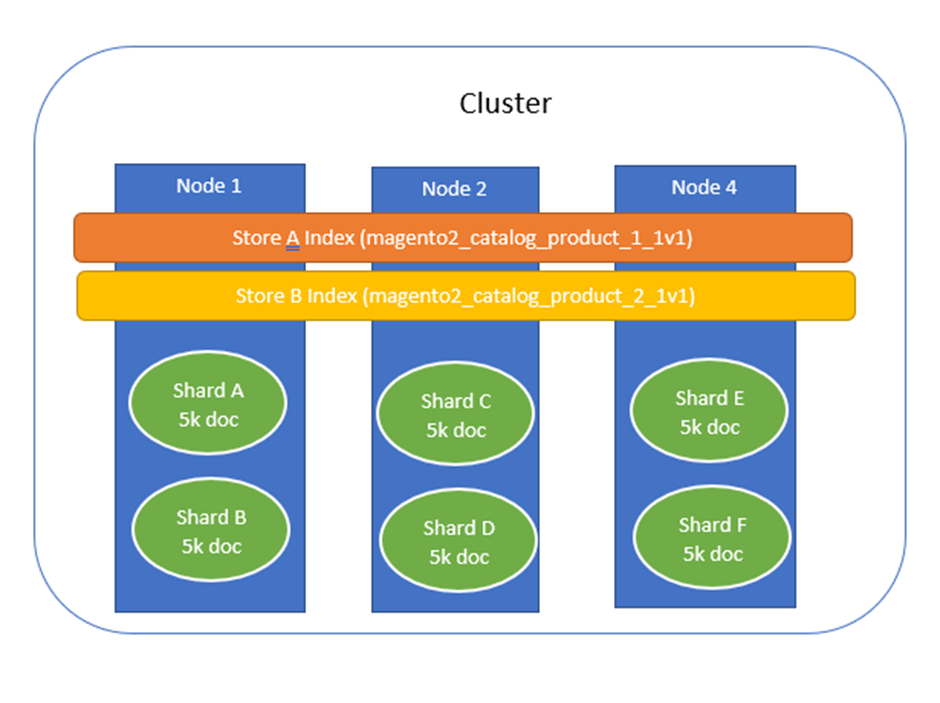
There are two main reasons why sharding is important,
- With the first one being that it allows you to split and thereby scale volumes of data.
- The other reason is that operations can be distributed across multiple nodes and thereby parallelized. This results in increased performance because multiple machines can potentially work on the same query.
To Avoid data loss, use replica of shards.
A cluster with too many indices or shards is said to suffer from oversharding. An oversharded cluster will be less efficient. The best way to prevent oversharding and other shard-related issues is to create a sharding strategy.
Index Mapping
Every index in an elastic search contains a mapping.
Mapping determines how a document, and its field are stored and indexed. It will define which fields needs to be indexed and which not. Mapping plays a important role in how ES stores and searches the data. Depending upon the use cases the mapping can be customized to make storage and indexing more efficient.
If a mapping is not defined, Elasticsearch defined its own mapping based on the document data this is called dynamic mapping.
A sample mapping is shown below.
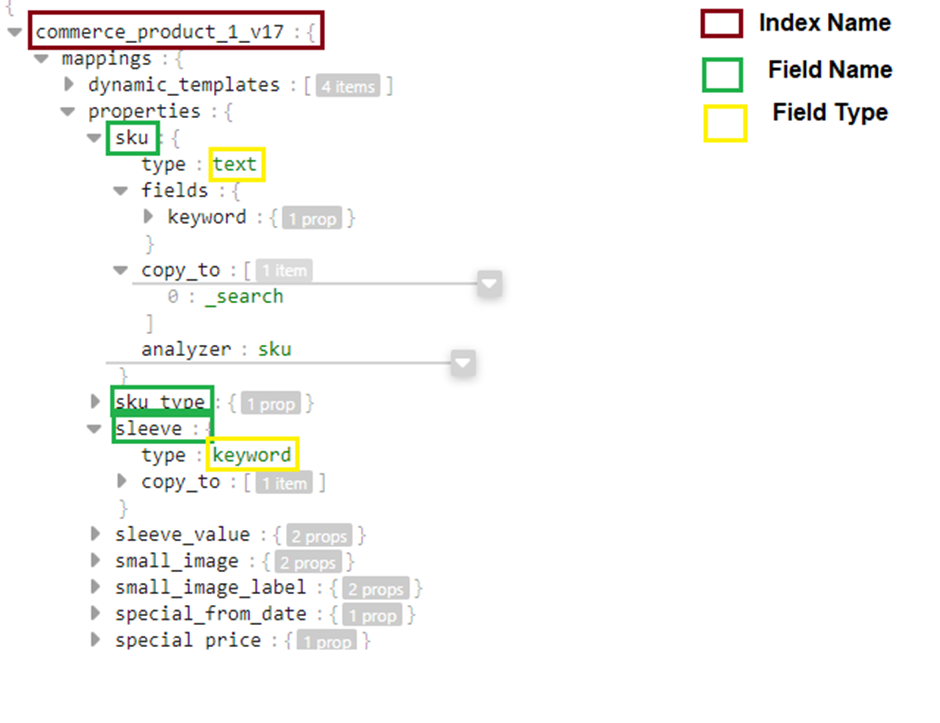
The data is Elasticsearch is stored as TEXT or KEYWORD. By Default, every string get mapped by both text and keyword. This can be changed based on our requirement.
Only One mapping will be created for a index, After the mapping is created we cannot edit the existing field but we can add new fields to mapping. If we need to edit the existing mapping, we need to delete the indices and create a new once.
Elasticsearch Indexing
When a document is stored, it is indexed and fully searchable in near real-time--within 1 second. Elasticsearch uses a data structure called an inverted index that supports very fast full-text searches. An inverted index lists every unique word that appears in any document and identifies all the documents each word occurs in.
Any field in Elasticsearch can be of type Text or Keyword.
- Text --> Full Text Search
- Keyword --> Keyword is defined for Exact Search, Aggregation and Sorting.
Text Field Indexing
Lets see how the text field indexing works, For our ex we will take the product attribute description which contains the below text mapping
"description": {
"type": "text"
}
and the data that we are inserting is “These pineapples are sourced from New Zealand.”
By default, strings are analyzed when it is indexed. The string is broken up into individual words also known as tokens. The analyzer further lowercases each token and removes punctuations.
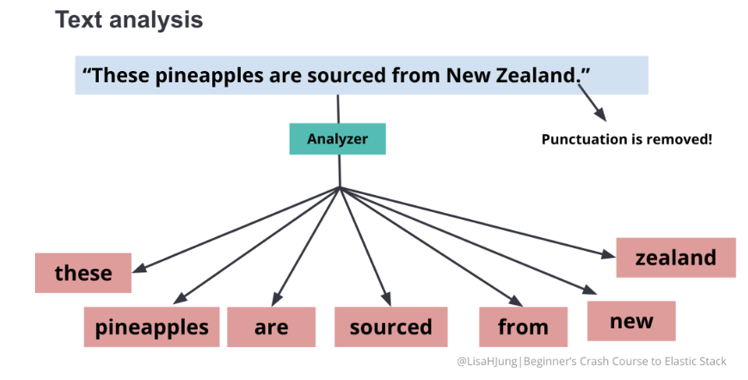
Once the text are analyzed its stored in the inverted Index
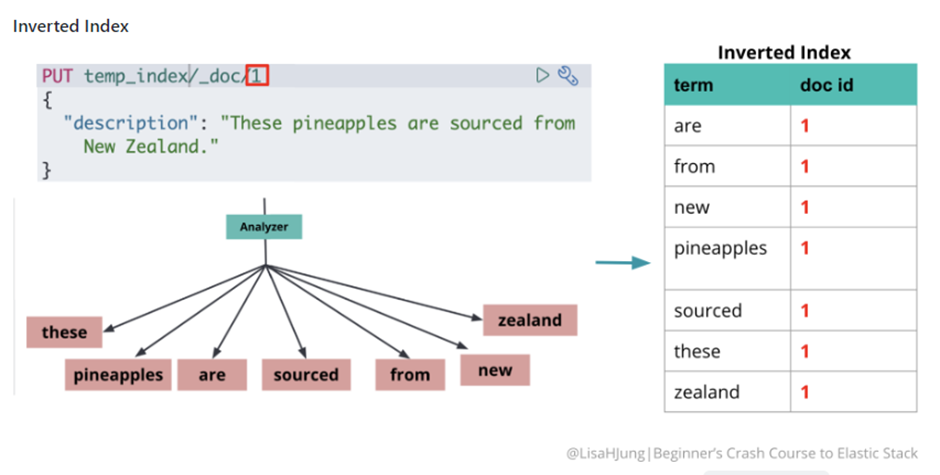
Now that we have the data indexed if the client is searching for the word pineapples, The ES just need to look for the term pineapples in the inverted index and be able to find the doc id.
In short inverted index is
- words --> to --> documents.
Only text fields support the analyzer mapping parameter.
Keyword Field Indexing
When a keyword field is created, the content of the field is not analyzed and not stored in the inverted index instead Elasticsearch uses a data structure call the DOC value

So for each document, the document id along with the field value the actual string is stored as is. This data structure is optimal for exact search aggregation and sorting.
Search Relevance & Full text Search
A search is made up of 2 parts Relevance and Ranking
Relevance:
All Relevant documents that match a certain query. Precision / Quality(AND) and Recall /Quantity ( OR) determines which document are relevant for the search query but it will not determine which is the most relevant compared to the other.
i.e Precision and Recall will include all the available "Phones" but it will not tell which phone should be listed first.
Ranking:
This determines which record should come first. Ranking of a document is determined by score using a scoring algorithm. A score is a value that represents how relevant a document for a specific query. A score for a document is determined by multiple factors such as
Term Frequency
How Often the search term appears in this document. More frequency == More often
Inverse Document Frequency
How often does this term appear in all the documents. The more often the lower the weight. For ex Buy Mobile for Rs 10000
Here Buy and for will appear more in all the document which will reduce its weight
Vector Space Model
This provides a way for comparing a multi term query against a document.
Field Length normalization
How long is the field, The shorter the higher the weight ex title vs body
Aggregation
There are 2 main ways to fetch data from Elasticsearch.
Query
- Retrieve document that matches the specific search criteria. Ex Search All Products with Name “Mobile Phones”
Aggregation
- Summarizes your data as metrics, statistics and other analytics Ex What is the total no of Mobiles that belongs to Apple Brand
Elasticsearch organizes aggregations into three categories:
Metric Aggregation
Aggregations that calculate metrics, such as a sum or average, from field values.
Bucket aggregations
When you want to aggregate document on several subset of documents based on the field value, range or other criteria bucket aggregation will be handy. Bucket aggregation groups documents into several set of documents called Bucket all document within a bucket share a same criteria.
Pipeline aggregation
Aggregations that take input from other aggregations instead of documents or fields are called pipeline aggregation.
The below is a sample aggregation query.
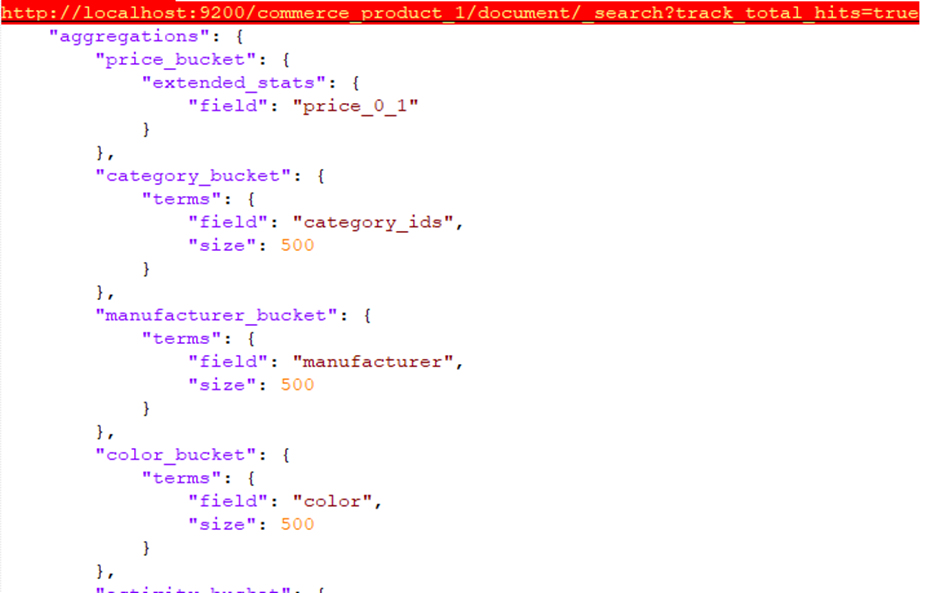

===============================================================================================================
Indices
Document that shares similarities are grouped in to indices. Multiple Index can be stored in a node. Index is just a virtual thing that knows where the data is stored, Data is actually stored in the shard.
MySQL => Databases => Tables => Columns/Rows
Elasticsearch => Indices => Types => Documents with Properties
===============================================================================================================
According official document, Mapping Types has been removed from es7,
reference https://www.elastic.co/guide/en/elasticsearch/reference/7.17/removal-of-types.html#_why_are_mapping_types_being_removed